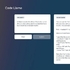
기술 개념도 (출처: 오태현 포스텍 교수)")
챗GPT, GPT-4가 산업혁명을 이끈 증기기관 발명에 비견되고 있지만, 텍스트와 이미지 중심인 GPT 시리즈가 아직 다루지 못하는 영역이 있다.
바로 영상 생성 기술이다. 그런데 국내 연구진이 영상 인공지능(AI) 기술에서 괄목할만한 성과를 잇달아 내놔 독자적인 파운데이션 모델(근간이 되는 AI) 기술이 귀한 국내 AI 업계에 희소식을 전하고 있다.
14일 AI 업계와 학계에 따르면 오태현 포스텍 교수 연구팀은 AI가 소리만 듣고 시각 장면을 영상으로 재현하는 기술을 오는 6월 캐나다 밴쿠버에서 열리는 세계 최고 권위의 AI 학회 'CVPR'에서 발표할 예정이다.
'사운드 투 신'(Sound2scene)으로 이름 붙인 연구는 말 그대로 소리 정보를 영상으로 바꿔주는 기술에 관한 것이다.
가령 참새 소리를 AI에 입력하면 나뭇가지에 앉아 지저귀는 참새 영상이 자동 생성된다.
오 교수는 "사람은 방 안에서도 바깥에서 들리는 놀이터 아이들 노는 소리, 자동차 경적 등을 듣고 놀이터 풍경이나 자동차가 지나가는 장면을 상상할 수 있듯 인공지능도 소리를 듣고 배경이 되는 장면을 만들어낼 수 있는 것"이라고 설명했다.
하지만 AI라고 해서 아무나 영상을 쉽게 생성할 수 있는 것은 아니다. 영상 생성은 이미지보다 훨씬 역동적이고 고차원적인 데이터와 기술력이 필요한 분야기 때문이다. 스테이블 디퓨전, 미드저니 등 세계적으로 인정 받는 이미지 생성 AI는 나와 있지만 영상 AI는 아직 없는 것은 이 이유에서다.
그는 "소리와 영상의 연관성을 찾기는 매우 어려운 문제로 우리 연구 이전에도 소리로부터 영상을 생성하는 연구가 있었지만, 인식이 불가할 정도의 기술력이 낮은 수준이었다"며 "세계 최초로 인식이 가능한 정도의 소리-영상 전환 기술을 개발한 것"이라고 기술 차별성을 자신했다.
오 교수 연구진은 2019년 목소리로부터 사람 얼굴을 복원하는 기술을 개발한 적이 있다. 이를 확장한 영상 생성 기술이라고 그는 설명했다.
기술 개발을 위해 오 교수 연구진은 다양한 사례에서 발생하는 소리를 모아둔 유튜브 클립 수십만 개를 분석했다.
이 기술을 활용하면 소리라는 데이터에 인식표를 붙이는 '라벨링'을 할 수 있기 때문에 음향 프로듀서가 데이터베이스 내에서 다양한 효과음을 찾을 때 일일이 들어봐야 하던 불편을 덜 수 있다.
오 교수 연구팀은 소리를 텍스트로 묘사하고 읽어주는 AI 모델도 개발했다.
6월 그리스에서 열리는 음성 신호 처리 분야의 권위 있는 학회 'ICASSP'에서 발표될 예정인 '사운드 투 텍스트' 기술은 청각 장애인이 소리 대신 글로 정보를 습득할 수 있도록 돕는 기술로도 주목된다.
연구팀은 영상 생성 기술뿐 아니라 생성형 AI의 데이터 수요 문제를 해결하는 방안도 고안했다고 한다.
소량의 실제 데이터를 활용해 AI가 합성 데이터를 생산하는 파이프라인을 개발한 것으로, 영상 속 움직임이나 3차원 내 거리(뎁스) 추정 등 문제에서 합성 데이터를 써서 실제 데이터로 학습한 모델보다도 뛰어난 AI 모델을 만들 수 있게 된다고 오 교수 연구팀은 설명했다.
이 기술은 지난 3월에 삼성휴먼테크 논문상 동상을 수상하기도 했다.
오 교수 연구팀이 개발한 영상 속 미세한 움직임을 증폭해 크게 보여주는 기술은 포스코 공장에서 시범 활용되고 있기도 하다.
오 교수는 "영상 생성 기술로 로봇의 인지 능력을 고도화하고 합성 데이터 생성 기술로 AI 산업 효율화에 기여할 수 있을 것"이라고 기대했다.
한편, 오 교수는 고등학교를 자퇴하고 자동차 정비공을 하다 미국 매사추세츠공과대학(MIT) 등에서 유학한 뒤 포스텍 교수로 임용된 입지전적인 인물로도 알려져 있다.
헬로티 김진희 기자 |